

Unsupervised Learning explained
text
Unsupervised learning in machine learning
In this post, we'll be discussing the concept of unsupervised learning. In our previous post on supervised learning, we talked about how supervised learning occurs when the data in our training set is labeled.

Unlabeled data
In contrast to supervised learning, unsupervised learning occurs when the data in our training set is not labeled.
Unsupervised learning occurs with unlabeled data.
With unsupervised learning, each piece of data passed to our model during training is solely an unlabeled input object, or sample. There is no corresponding label that's paired with the sample.
Hm... but if the data isn't labeled, then how is the model learning? How is it evaluating itself to understand if it's performing well or not?
Well, first, let's go ahead and touch on the fact that, with unsupervised learning, since the model is unaware of the labels for the training data, there is no way to measure accuracy. Accuracy is not typically a metric that we use to analyze an unsupervised learning process.
Essentially, with unsupervised learning, the model is going to be given an unlabeled dataset, and it's going to attempt to learn some type of structure from the data and will extract the useful information or features from this data.
It's going to be learning how to create a mapping from given inputs to particular outputs based on what it's learning about the structure of this data without any labels.
Unsupervised learning examples
Let's make this solid with some examples.
Clustering algorithms
One of the most popular applications of unsupervised learning is through the use of clustering algorithms. Sticking with our example from our previous post on supervised learning, let's suppose we have the height and weight data for a particular age group of males and females.
This time, we don't have the labels for this data, so any given sample from this data set would just be a pair consisting of one person's height and weight. There is no associated label telling us whether this person was a male or female.
Now, a clustering algorithm could analyze this data and start to learn the structure of it even though it's not labeled. Through learning the structure, it can start to cluster the data into groups.
We could imagine that if we were to plot this height and weight data on a chart, then maybe it would look something like this with weight on the x-axis and height on the y-axis.
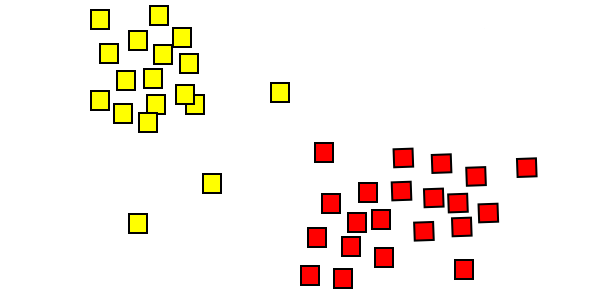
There's nothing explicitly telling us the labels for this data, but we can see that there are two pretty distinct clusters here, and so we could infer that perhaps this clustering is occurring based on whether these individuals are male or female.
One of these clusters may be made up predominately of females, while the other is predominately male, so clustering is one area that makes use of unsupervised learning. Let's look at another.
Autoencoders
Unsupervised learning is also used by autoencoders.
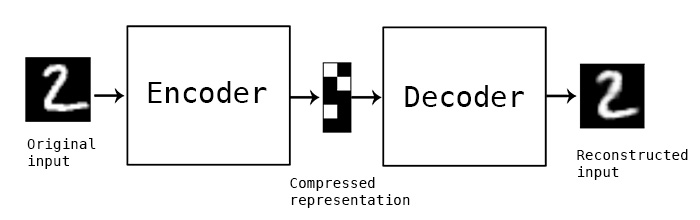
In the most basic terms, an autoencoders is an artificial neural network that takes in input, and then outputs a reconstruction of this input.
Based on everything we've learned so far on neural networks, this seems pretty strange, but let's explain this idea further using an example.
The example we'll use is written about in a blog by François Chollet, the author of Keras, the neural network API we've used in several posts.
Suppose we have a set of images of handwritten digits, and we want to pass them through an autoencoder. Remember, an autoencoder is just a neural network.
This neural network will take in this image of a digit, and it will then encode the image. Then, at the end of the network, it will decode the image and output the decoded reconstructed version of the original image.
The goal here is for the reconstructed image to be as close as possible to the original image.

A question we might ask about this process is: How can we even measure how well this autoencoder is doing at reconstructing the original image without visually inspecting it?
Well, we can think of the loss function for this autoencoder as measuring how similar the reconstructed version of the image is to the original version. The more similar the reconstructed image is to the original image, the lower the loss.
Since this is an artificial neural network after all, we'll still be using some variation of SGD during training, and so we'll still have the same objective of minimizing our loss function.
During training, our model is incentivized to make the reconstructed images closer and closer to the originals.
Applications of autoencoders
Alright, so hopefully we have the very basic idea of an autoencoder down, but what would be an application for doing this? Why would we just want to reconstruct input?

Well, one application for this could be to denoise images. Once the model has been trained, then it can accept other similar images that may have a lot of noise surrounding them, and it will be able to extract the underlying meaningful features and reconstruct the image without the noise.
If you'd like to read-up further on the idea of autoencoders, check out this blog.
Wrapping up
We should now understand the concept of unsupervised learning, as well as some of the applications that make use of this type of learning like clustering algorithms and autoencoders. I'll see ya in the next one!
quiz
 DEEPLIZARD
Message
DEEPLIZARD
Message
resources
updates
Committed by on